



suivant: L'interface graphique
monter: SOUTENANCE FINALE MARVIN (Modest-encoding
précédent: Traitement du signal Création
Table des matières
Sous-sections
Le but lorsque l'on utilise Marvin, c'est de chiffrer ses documents. Après plusieurs axes de reflexion, nous nous sommes finalement décidé sur un chiffrement symétrique. Bien que la cryptographie asymétrique possède l'avantage d'échanger les fichiers sans contrainte d'interception, nous n'avons pas trouvé pour Marvin un protocole de cryptage fiable. Nous avions notamment un problème de sécurité au niveau de l'échange des empreintes vocales. De plus la lenteur de ces derniers nous a fait définitivement pencher vers un procédé symétrique. Finalement, le programme utilise l'algorithme de chiffrement IDEA pour encoder les fichiers et la fonction de hachage MD5 pour stocker la clef sur le disque dur.
pt
D'un point de vue technique, IDEA (International Data Encryption Algorithm) est basée sur la théorie des ensemble et la principale ``astuce'' réside sur la difficultés d'inverser les nombres dans un corps intègre abélien (Z/pZ). Curieusement, l'algorithme de chiffrage n'utilise que trois opérations simples qui sont l'addition modulo 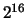 , la multiplication modulo
, la multiplication modulo  , et le ou exclusif bit à bit (xor). Remarquons que est un nombre premier, ce qui donne les propriétés intérréssantes de l'ensemble comme l'intégrité. Ces trois opérations sont utilisées dans un schéma de dix étapes qui opère sur des blocs de 16 bits. Ces blocs sont, soit le texte à chiffrer découpé dans cette dimension, soit une des sous clef de même taille. Nous étudierons plus tard l'utilisation des clefs. Ce schéma est lui même répété huit fois, ce qui nous donne le squelette d'IDEA.
, et le ou exclusif bit à bit (xor). Remarquons que est un nombre premier, ce qui donne les propriétés intérréssantes de l'ensemble comme l'intégrité. Ces trois opérations sont utilisées dans un schéma de dix étapes qui opère sur des blocs de 16 bits. Ces blocs sont, soit le texte à chiffrer découpé dans cette dimension, soit une des sous clef de même taille. Nous étudierons plus tard l'utilisation des clefs. Ce schéma est lui même répété huit fois, ce qui nous donne le squelette d'IDEA.
schéma fonctionnel d'une ronde IDEA
pt
IDEA a besoin d'une clef de 128 bits ce qui correspond à un mot de passe d'au maximum 16 caractères (si celui fait moins de 16 caractères, il sera complété par des zéros). Nous avons vu qu'IDEA utilisait des blocs de 16 bits, il faut donc concevoir les sous clefs. L'algorithme en utilise 52 sous clefs (6 pour chacune des 8 rondes et 4 pour la transformation finale).
pt
D'abord, la clef de 128 bits est divisée en 8 sous clefs de 16 bits. Ce sont les 8 premières sous clefs pour l'algorithme (les 6 de la première ronde et les 2 premières de la deuxième ronde). Ensuite la clef est décalée circulairement de 25 bits vers la gauche et à nouveau divisée en 8 sous clefs. Les 4 premières sont utilisées lors de la deuxième ronde et les 4 autres lors de la troisième ronde. La clef est à nouveau décalée circulairement de 25 bits vers la gauche pour les 8 sous clefs suivantes, et ainsi de suite jusqu'à la fin de l'algorithme.
pt
Le déchiffrement est exactement le même, excepté que les sous clefs sont inversées et légèrement différentes. Les sous clefs de déchiffrements sont inverses par rapport à l'addition ou par rapport à la multiplication des sous clefs de chiffrement (pour les besoins d'IDEA, tous les sous blocs constitués uniquement de zéros représentent 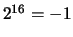 modulo pour la multiplication ; et l'inverse de la multiplication de 0 est donc 0. Calculer ces inverses prend du temps mais vous ne devez le faire qu'une seule fois par clef de déchiffrement. La seule technique pour calculer ces inverses de façon raisonnable reste d'essayer les possibilités jusqu'à trouver
modulo pour la multiplication ; et l'inverse de la multiplication de 0 est donc 0. Calculer ces inverses prend du temps mais vous ne devez le faire qu'une seule fois par clef de déchiffrement. La seule technique pour calculer ces inverses de façon raisonnable reste d'essayer les possibilités jusqu'à trouver
 .
pt
Le tableau ci dessous indique les sous-clefs de chifremment et les sous clefs de déchiffrement correspondantes.
.
pt
Le tableau ci dessous indique les sous-clefs de chifremment et les sous clefs de déchiffrement correspondantes.
| Ronde |
Sous clefs de chiffrement |
Sous clefs de déchiffrement |
| 1 |
 |
 |
| 2 |
 |
 |
| 3 |
 |
 |
| 4 |
 |
 |
| 5 |
 |
 |
| 6 |
 |
 |
| 7 |
 |
 |
| 8 |
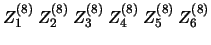 |
 |
| finale |
 |
 |
MD5 est une fonction de hachage à sens unique, c'est à dire qu'il est impossible de retrouver le texte original en possédant celui haché (la fonction n'est pas bijective). Les initiales MD signifie "Message Digest" et 5 correspond au numéro de version. Il a été développé par Rivest et constitue en fait une améliorations d'un algorithme précédent MD4.
Il existe une librairie fournie avec Linux proposant la fonction MD5 mais nous avons trouvé plus interressant de se pencher plus précisemment sur son fonctionnement pour la programmer.
Description
Après un traitement initial, MD5 manipule le texte d'entrée par blocs de 512 bits divisée en 16 sous-blocs de 32 bits. La sortie de l'algorithme est un ensemble de 4 blocs de 32 bits qui, joint ensemble, forment une seule empreinte de 128 bits.
Tout d'abord le message est complété de manière à ce que 64 bits de plus amèneraient sa longueur à un multiple de 512. Ce remplissage se fait d'un seul 1 rajouté à la fin du message suivi d'autant de 0 que nécessaire. Ensuite, une représentation de la longueur totale du message codé sur 64 bits est jointe
au résultat (avant le remplissage). Ces deux étapes servent à rendre la longueur du message multiple de 512 bits (ce qui est nécessaire pour la suite de l'algorithme), la taille du fichier permet d'éviter les similitudes entre les messages après le remplissage.
Quatre variables de 32 bits sont initialisées :
On les appelle variables de chaînage.
Maintenant la boucle principale de l'algorithme commence, elle sera effectuée autant de fois qu'il y a de blocs de 512 bits dans le message à traiter. Les quatre variables de chaînage sont sauvegardées dans quatre autres variables.
La boucle principale a 4 rondes. Chaque ronde consiste en 16 exécutions d'une opération. Chaque opération calcule une fonction non linéaire de trois des variables A, B, C et D. Ensuite elle ajoute au résultat la quatrième variable, un sous bloc du texte à chiffrer et une constante. Ce nouveau résultat est ensuite décalé circulairement vers la gauche d'un nombre variable de bits et ensuite ajouté à l'une des A, B, C ou D. Enfin, ce dernier résultat remplace l'une des A, B, C, D pour les opérations suivantes.
Voici les quatre fonctions non linéaires, une différentes pour chaque ronde :
- F(X,Y,Z) = (X & Y) | (!X & Z)
- G(X,Y,Z) = (X & Z) | (Y & !Z)
- H(X,Y,Z) = X ^ Y ^ Z
- I(X,Y,Z) = Y ^ (X | !Z)
& : et logique bit à bit
! : négation
| : ou inclusif
: ou exclusif
Voici les quatre opérations des quatre rondes :
 (A,B,C,D,M[i],
(A,B,C,D,M[i],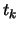 ) équivaut à A = B + ((A + F(B,C,D) + M[i] + ) <s)
) équivaut à A = B + ((A + F(B,C,D) + M[i] + ) <s)
 (A,B,C,D,M[i],) équivaut à A = B + ((A + G(B,C,D) + M[i] + ) <s)
(A,B,C,D,M[i],) équivaut à A = B + ((A + G(B,C,D) + M[i] + ) <s)
 (A,B,C,D,M[i],) équivaut à A = B + ((A + H(B,C,D) + M[i] + ) <s)
(A,B,C,D,M[i],) équivaut à A = B + ((A + H(B,C,D) + M[i] + ) <s)
 (A,B,C,D,M[i],) équivaut à A = B + ((A + I(B,C,D) + M[i] + ) <s)
(A,B,C,D,M[i],) équivaut à A = B + ((A + I(B,C,D) + M[i] + ) <s)
M[i] représente le ième sous bloc du message (i allant de 0 à 15), <s représente le décalage circulaire à gauche de s bits et aux différentes constantes.
suivant: L'interface graphique
monter: SOUTENANCE FINALE MARVIN (Modest-encoding
précédent: Traitement du signal Création
Table des matières
root
2002-06-18
![\includegraphics[]{idea.ps}](img276.png)